Why build a globally distributed, multi-region identity and access platform
Learn how to build a multi-region, globally distributed system based on open source and technologies like Kubernetes, ArgoCD, Crossplane, Grafana, and CockroachDB.


Founder & CTO
As the world becomes increasingly interconnected, businesses are no longer serving customers in a single geographic region. This shift towards a global marketplace brings with it new challenges when it comes to identity and access management (IAM).
At Ory, we recognized that our customers needed a solution that could meet where our customers' users are: everywhere in the world. These users expect the service to be fast, reliable, and compliant with local laws.
In this blog post, you will learn why Ory built a globally distributed system for identity and access management. This blog post is for you if you want to learn what multi-region means and why it is important.
Ory runs a global identity and access (IAM) platform (Ory Network), based on open source, that companies use to solve login, registration, permissions, user management, and advanced topics like OAuth2 and OpenID Connect. Ory Network is the only multi-region IAM in the world.
:::info
Companies using Ory Network reduce risk, lower their TCO, reduce time-to-market, and win over users with ultra-fast websites and apps. Every day, Ory is handling around 3 billion API requests in more than 11.000 production environments worldwide.
:::
Why multi-region
We will explore the fundamental benefits of a multi-region architecture throughout the article. The most compelling reasons to build a multi-region architecture is that modern software applications need to be fast everywhere in the world, always on and reliable like google.com, and compliant with laws and regulations like GDPR. Multi-region architectures help solve these issues efficiently and effectively. At the same time, multi-region architectures are not easy to build, and this article explores how Ory achieved this milestone for its IAM product: Ory Network.
Single- and multi-regions
In this section, we will explore the fundamental differences between single region and multi-region architecture, two contrasting approaches in designing and deploying cloud-based systems.
Availability zones are not regions
Cloud platform regions and availability zones are two distinct concepts that people often confuse. Regions refer to geographic locations where cloud providers have their data centers, and each region operates independently. Data stored in one region is not automatically replicated in others, meaning that an outage in a region only affects applications and data within that specific region. Availability zones, on the other hand, are isolated areas within a region, each with its own data center. Deploying across multiple availability zones enhances redundancy and availability, allowing applications and data to fail over to another zone in case of an outage. However, some cloud providers may have separate availability zones located in the same physical data center, which can pose risks during catastrophic events. For example, the failure of all three availability zones in Google Cloud Platform's europe-west9 region was caused by a fire in the data center where all three zones were located, despite each zone having independent resources.
Single region architecture
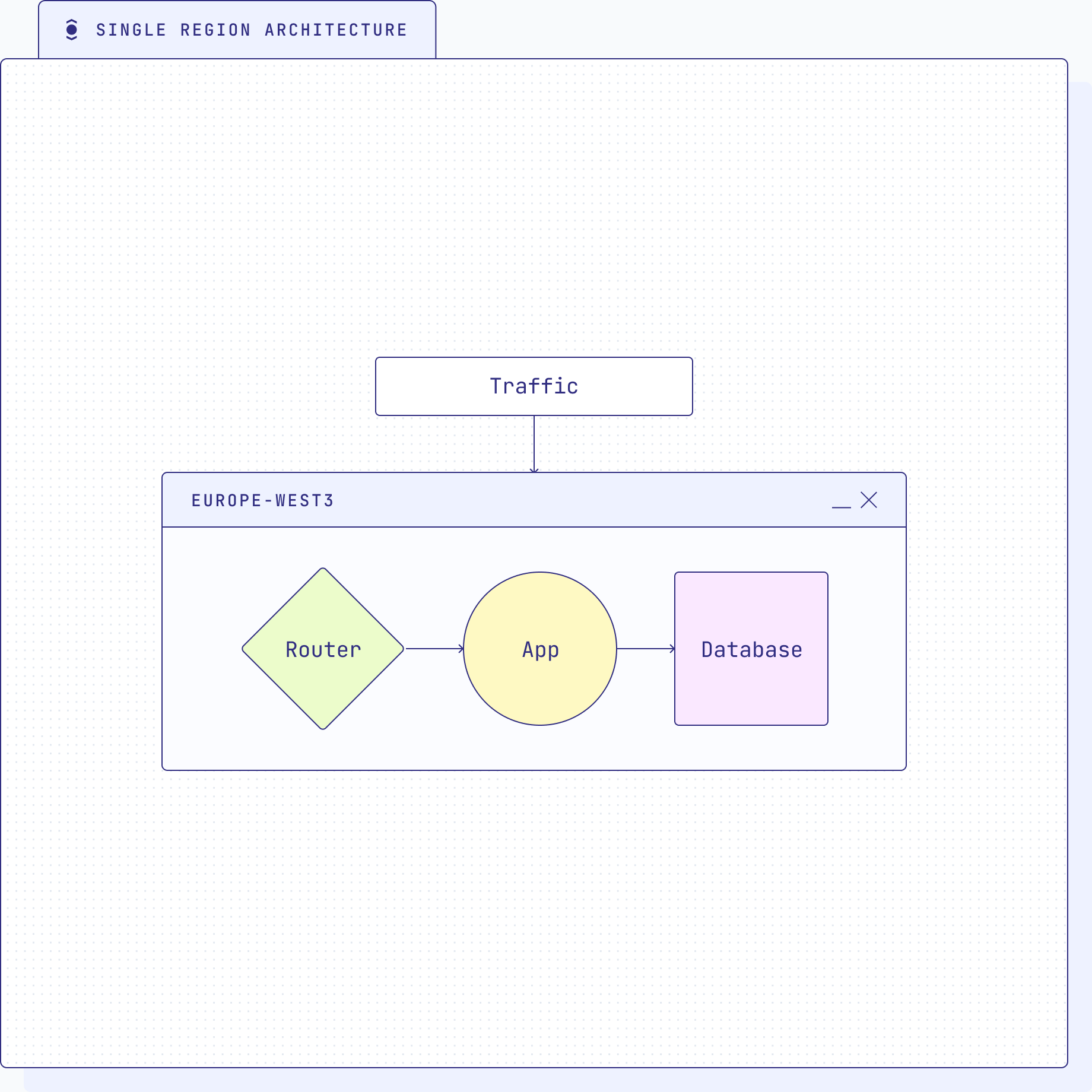
Single region architecture can be problematic for several reasons, primarily because it lacks the necessary redundancy and fault tolerance to handle various types of failures.
- Increased risk of downtime: In a single region architecture, if the entire region experiences an outage due to natural disasters, infrastructure failures, or other unforeseen events, the application and services hosted in that region will become inaccessible. This can lead to prolonged downtime and significant disruption to business operations.
- Data loss and corruption: Without data replication across regions, a catastrophic failure in the single region could result in data loss or corruption. If backups and recovery processes are not robust, recovering lost data may be difficult or impossible.
- Limited disaster recovery: In a single region setup, disaster recovery options are constrained. If the primary region faces a disaster, the lack of geographically distributed resources makes it challenging to switch to an alternative location and recover quickly.
- Performance bottlenecks: Having a single region could lead to performance bottlenecks, especially if the user base is spread across different geographical locations. Users farther away from the data center may experience increased latency and slower response times.
- Vulnerability to network failures: A single region is more susceptible to network connectivity issues. If there is a network outage that affects the region, all services hosted within that region could be impacted.
Single region architecture in multiple regions
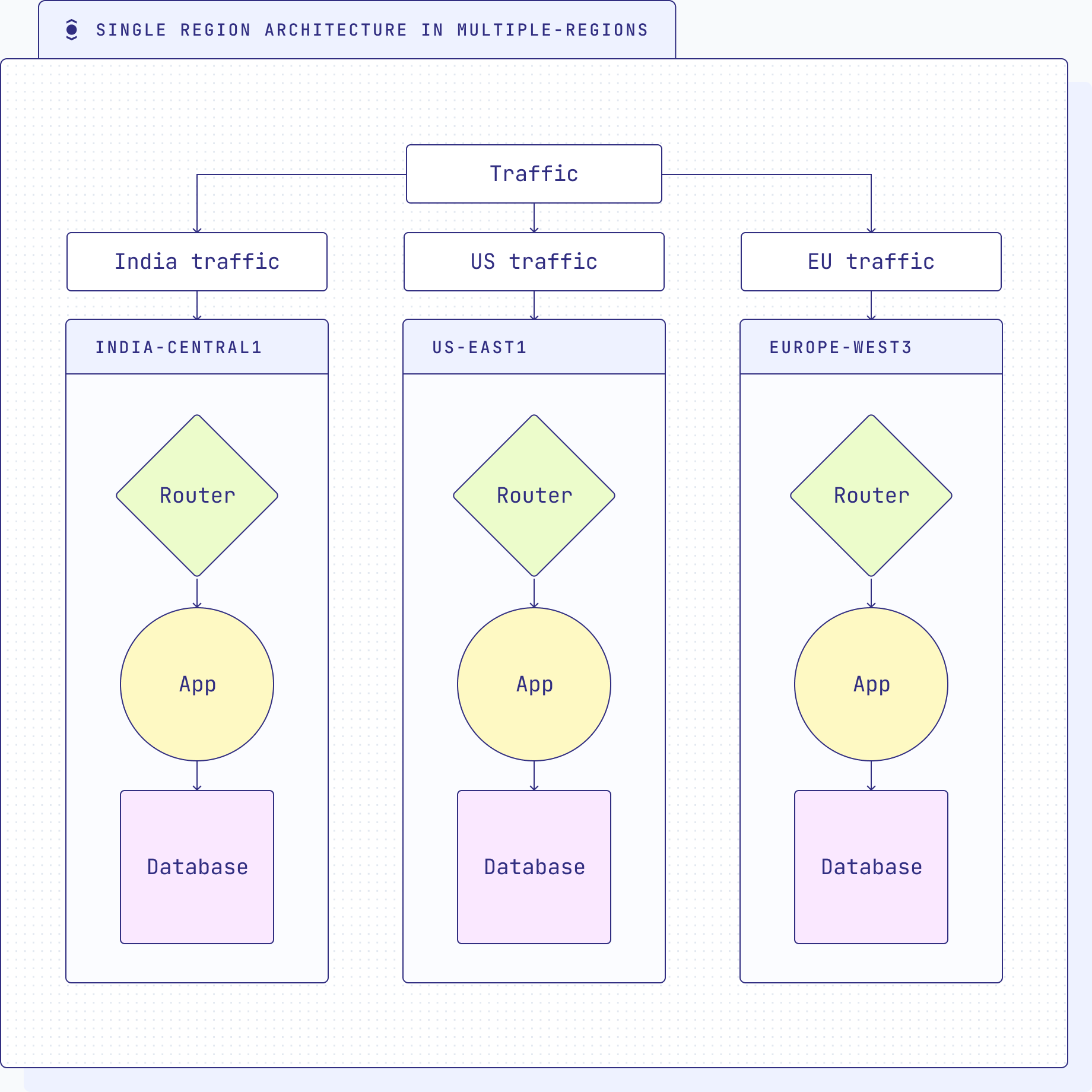
A single region architecture involves deploying a copy of the entire software stack in each location. Deploying a single region architecture in multiple regions to reduce latency and address compliance concerns might seem like an attractive approach at first glance. However, it still shares many of the drawbacks and limitations inherent in a traditional single region architecture.
- Data fragmentation and inconsistency: While deploying the architecture in multiple regions may improve latency for users in those regions, it introduces data fragmentation and inconsistency across regions. Each region operates independently, resulting in potential disparities in data sets and configurations. This can lead to challenges in data synchronization, data consistency, and maintaining a unified view of data across regions.
- Increased management overhead: Adopting the same architecture in multiple regions means maintaining multiple production deployments, each with its own set of codebases (GitOps), configurations, and updates. This can lead to increased complexity in software management, making it challenging to roll out updates, bug fixes, and new features consistently across all regions.
- Data merge and movement complexity: Moving and merging data between multiple regions in a replicated architecture can be complex and error-prone. Transferring data between regions for load balancing or compliance purposes requires careful planning and execution to avoid data inconsistencies or potential data loss.
- Increased operational overhead: Running multiple instances of the same architecture in various regions requires additional management overhead. Each region needs separate monitoring, maintenance, and support, adding complexity to the overall system management.
Multi-region architecture
A multi-region architecture is challenging to build and run, but can address the limitations of the single-region architectures. Here, the data plane is replicated and shared and available in all regions. Stateless services are replicated the same regions as well. This approach has several advantages.
- Improved high availability: Multi-region architecture offers higher availability by distributing application instances across multiple regions. If one region goes down, traffic can be seamlessly routed to other functioning regions, ensuring continuous service availability.
- Disaster recovery and business continuity: With multiple regions, companies can implement robust disaster recovery plans. In case of a disaster or outage in one region, they can failover to other regions, minimising downtime and ensuring business continuity.
- Reduced latency: By hosting resources closer to end-users in different regions, companies can reduce latency and provide better user experiences.
- Enhanced data redundancy and security: Replicating data across regions ensures data redundancy, improving data resilience and mitigating the risk of data loss. It also enhances data security, as sensitive data can be stored in specific regions to comply with local regulations.
- Compliance and risk management: For companies with global operations, hosting data in multiple regions helps them comply with data sovereignty regulations and reduces risks associated with region-specific legal and compliance issues.
Multi-region Identity and Access Management
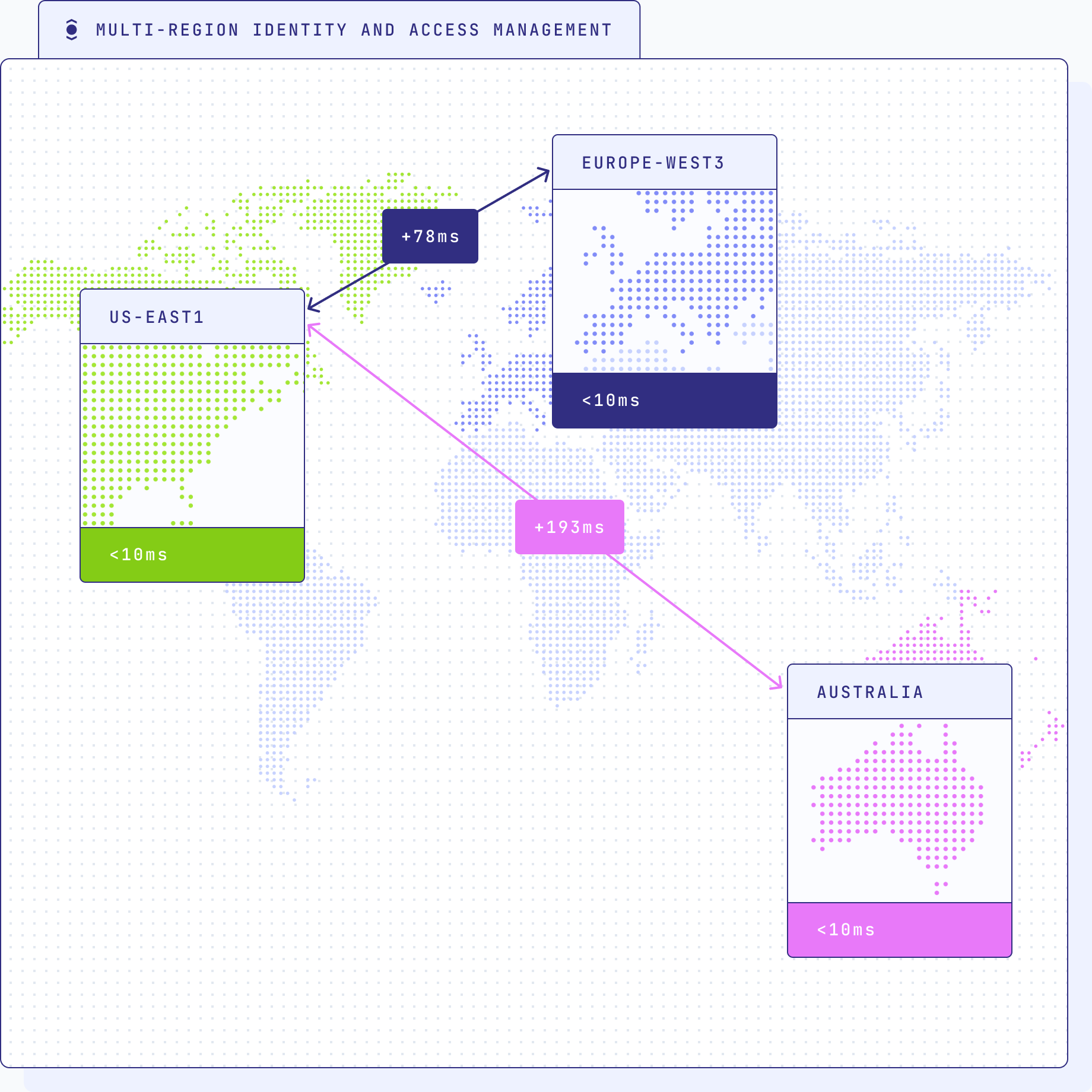
Ensuring robust identity and access management across multiple regions is a critical aspect of an organization's infrastructure. Multi-region IAM addresses several key challenges and requirements to provide a seamless and secure user experience while adhering to data regulations and ensuring high availability.
Low-latency access: Since identity and access management are integral to almost every user request made to a system, achieving low-latency response times is vital. With IAM services distributed across multiple regions, users experience reduced latency during identity verification and access authorization, enhancing overall system responsiveness and user satisfaction.
Enhanced availability and reliability: Multi-region IAM provides increased availability and reliability by offering redundancy across regions. In the event of a single-region failure or outage, users can seamlessly access applications and services from alternative regions, minimizing downtime and ensuring continuous availability. This level of fault tolerance is particularly crucial for critical services that need to be accessible at all times, irrespective of localized failures.
Compliance with data homing regulations: While having a unified IAM system is crucial, replicating user data across all regions can conflict with data homing regulations (GDPR, LGPD, PIPA, CCPA, …) that require storing data within a user's country. To address this challenge, organizations must strike a balance between centralizing IAM functions and adhering to regional data storage requirements. Implementing data sharding by geography allows organizations to scale their infrastructure based on regional demands while maintaining compliance with data regulations.
Unified user identity across regions: One of the primary concerns in multi-region architectures is maintaining a coherent and unified view of user identities and their permissions across all regions. Regardless of the user's home region, it is essential to have a centralized IAM system that can efficiently handle identity verification and access control for each user. This enables a consistent user experience, reduces complexity, and streamlines administrative tasks related to user management.
Dynamic scalability: The geographic sharding of data and IAM services enables organizations to scale their infrastructure dynamically based on regional demand. For instance, during peak times like Black Friday in the US, organizations can scale up the IAM infrastructure in that region to handle increased user traffic. Simultaneously, regions with lower demand can remain efficiently scaled, optimizing resource usage and cost efficiency.
Regulatory compliance and the need for data homing and encryption
The handling of personal data has become a complex legal challenge, with no clear global consensus on how such data can be moved between countries. Despite being close allies, even the European Union (EU) and the United States have struggled to establish stable legal frameworks for cross-border data transfers:
- Safe Harbor Agreement: The Safe Harbor agreement, which aimed to facilitate data transfers between the EU and the US, was invalidated after the revelations of Edward Snowden regarding US government surveillance practices. This decision highlighted the difficulties in ensuring data privacy in international data transfers.
- EU-US Privacy Shield: Subsequently, the EU and the US attempted to establish a successor to the Safe Harbor agreement through the Privacy Shield framework. However, the Court of Justice of the EU declared the Privacy Shield invalid due to concerns over US surveillance practices and the lack of adequate protection for EU citizens' personal data.
- EU-US Data Privacy Framework (Privacy Shield II): Currently, efforts are underway to establish a new EU-US data privacy framework. However, uncertainties persist regarding its approval, and the possibility of it facing legal challenges is very likely.
Given the evolving and diverse regulatory landscape worldwide, businesses face significant uncertainties in handling personal data across borders. Data homing can mitigate the risks associated with regulatory uncertainty and changes.
Data homing
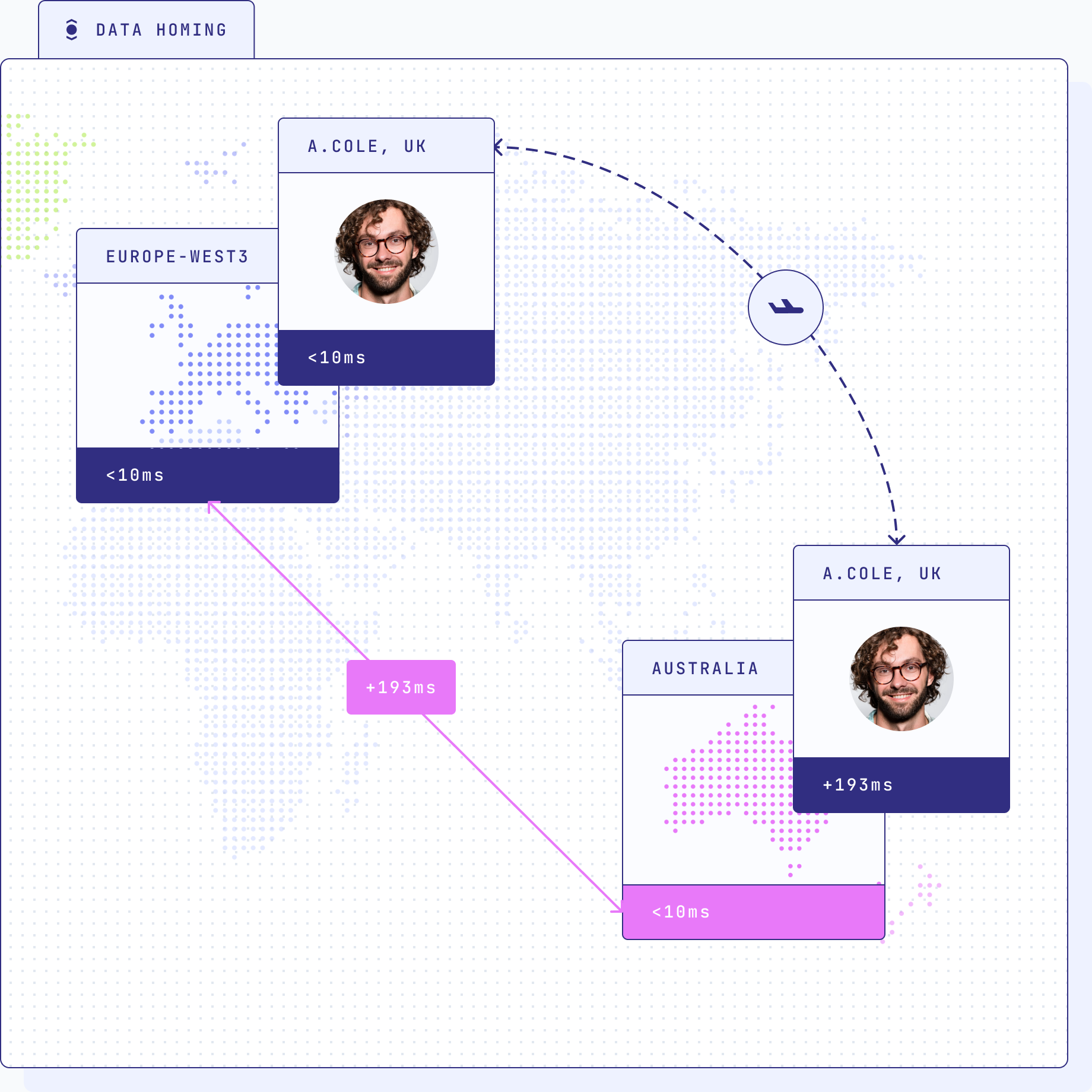 Data homing
involves storing personal data within the user's country of origin and complying
with data localization requirements that various countries may impose. This
strategy minimizes the risk of non-compliance with regional data protection laws
and ensures that sensitive data remains within the jurisdictional boundaries
where it is subject to specific legal protections.
Data homing
involves storing personal data within the user's country of origin and complying
with data localization requirements that various countries may impose. This
strategy minimizes the risk of non-compliance with regional data protection laws
and ensures that sensitive data remains within the jurisdictional boundaries
where it is subject to specific legal protections.
Encryption
While data homing provides a promising solution, it is not the only approach to safeguarding data privacy. Encryption, particularly advancements like homomorphic encryption, has gained attention as an alternative method. We considered this method, but it had to be ruled out in its current state.
Homomorphic encryption
Homomorphic encryption allows computations on encrypted data without the need for decryption, preserving data privacy throughout processing. This can be a powerful technique for protecting sensitive data during cross-border transfers and while stored in databases. Fully Homomorphic Encryption is not yet ready for market though:
Today, conventional wisdom suggests that an additional performance acceleration of at least another 1 million times would be required to make FHE operate at commercially viable speeds.
Column-Level Encryption in SQL databases
Implementing encryption at the column level in SQL databases offers another
layer of data protection. By encrypting specific columns containing sensitive
information, businesses can maintain data confidentiality while still supporting
necessary operations like unique constraints. Different approaches to
column-level encryption, such as deterministic and randomized encryption,
provide varying trade-offs between security and query performance. Popular
open-source databases (MariaDB, PostgreSQL, MySQL, CockroachDB) do not offer
advanced column-level encryption that can deal with constraints (foreign keys,
unique) and efficient range queries
(SELECT * FROM table WHERE encrypted_column > 'some_value').
We would have preferred column-level encryption for managing personal data, but there is no good solution available for this yet.
An exciting journey ahead
As Ory Network embarks on the next phase of its evolution, the organization remains steadfast in its commitment to delivering a resilient, compliant, and high-performance platform. With a clear vision for the future and a robust road map in place, Ory Network is poised to continue its mission of empowering developers and users alike, while embracing technological advancements and best practices in the ever-evolving realm of multi-region architecture.
Conclusion
You made it to the end, congratulations! I hope this article helped you understand why multi-region architectures are an important requirement for international operating businesses. If you like what you read, please try out Ory Network! It's free to play around, and we at Ory hope you enjoy the product as much as we enjoy building it!
Further reading

The future of Identity: How Ory and Cockroach Labs are building infrastructure for agentic AI

Ory and Cockroach Labs announce partnership to deliver the distributed identity and access management infrastructure required for modern identity needs and securing AI agents at global scale.

Ory + MCP: How to secure your MCP servers with OAuth2.1

Learn how to implement secure MCP servers with Ory and OAuth 2.1 in this step-by-step guide. Protect your AI agents against unauthorized access while enabling standardized interactions.